
Дигиталната основа на IT excellence: Разглеждане на основните ITSM процеси в ServiceNow
IT Service Management (ITSM) вече не е просто набор от вътрешни процедури; то е невидимият двигател, който поддържа всяко дигитално взаимодействие и бизнес процес. В ерата на дигиталната трансформация, гъвкавостта, стабилността и ефективността на ИТ определят успеха или провала на една компания.
Платформата ServiceNow се утвърди като лидер, предлагайки не просто инструменти, а единна System of Record, в която всички ИТ събития от проста заявка до критична инфраструктурна промяна се управляват на една платформа. Стабилната ITSM основа в ServiceNow се опира на синергията между четири основни стълба: Incident, Problem, Change и Request. Дълбокото разбиране на тези процеси е ключът към превръщането на ИТ от реактивен център на разходи в стратегически и проактивен партньор.
ЧАСТ I: Incident Management: Бързо възстановяване на услугите
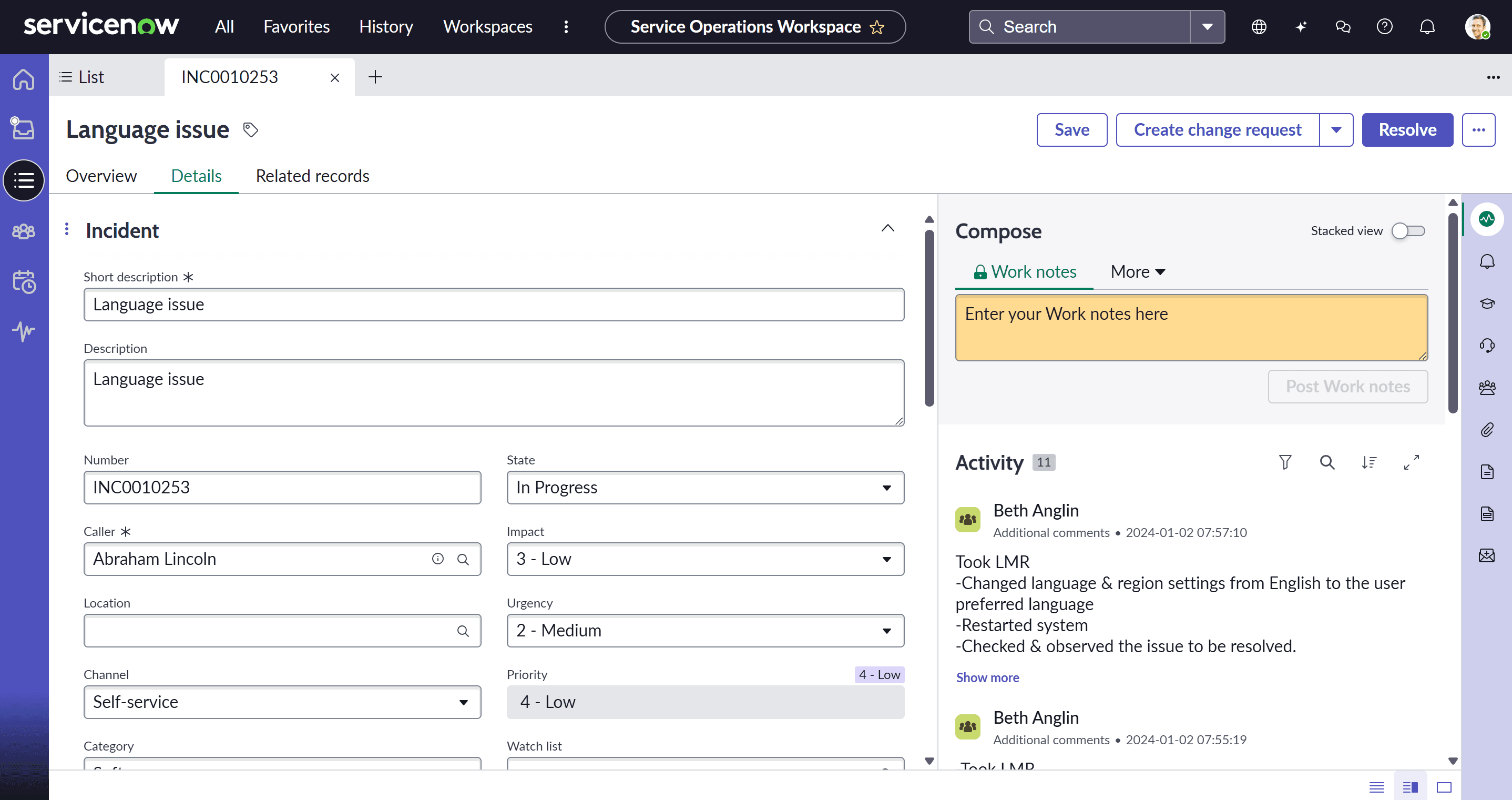
Incident Management е първата точка на контакт на потребителя с ИТ при прекъсване на услуга. Неговата основна цел е бързото възстановяване на нормалната работа на услугата с минимално въздействие върху бизнеса.
OOTB lifecycle в ServiceNow
- Регистриране и класификация: Инцидентът се създава чрез портала, имейл, телефон или автоматично чрез ITOM. Основни полета като Impact и Urgency се използват за автоматично изчисляване на Priority.
- Триаж и насочване: На база Priority и Category, инцидентът автоматично се насочва към правилната група за поддръжка чрез Assignment Rules.
- Разследване и диагностика: Агентът започва работа, като записва предприетите стъпки. Тук идват и най-новите иновации: Now Assist предлага контекстуални обобщения на предишни инциденти и създава чернови на отговори към потребителя, ускорявайки диагностиката.
- Решение и затваряне: След като услугата бъде възстановена, агентът документира решението. Инцидентът преминава в определен времеви период за потвърждение на решението (Resolution Time), което дава възможност на потребителя да потвърди, че проблемът е отстранен, преди окончателното затваряне.
Стойността на Incident Management се измерва чрез:
- Mean Time To Resolution (MTTR): Времето от отварянето на инцидента до неговото разрешаване. ServiceNow предлага Performance Analytics, за да идентифицира тесните места в процеса.
- Service Level Agreements (SLAs): Определяне и проследяване на времевите ангажименти за реакция и разрешаване според приоритета. Автоматизираните ескалации са ключов елемент от OOTB конфигурацията.
ЧАСТ II: Problem Management: От симптом към първопричина
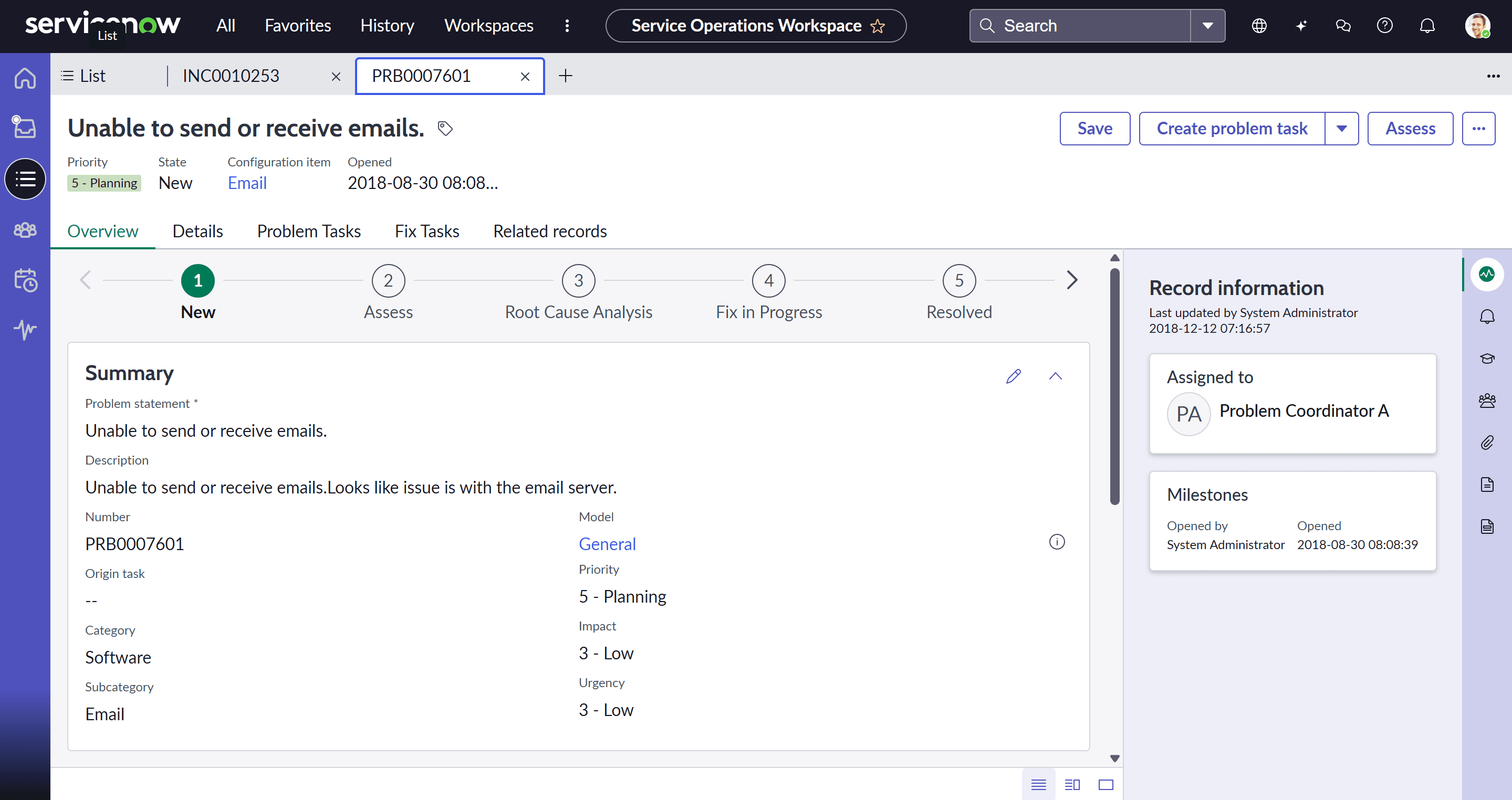
Ако Incident Management се занимава със симптомите, то Problem Management се занимава със самото заболяване. Неговата цел е да намали броя на инцидентите чрез идентифициране, анализиране и елиминиране на първопричините (Root Cause Analysis / RCA).
В ServiceNow един Problem често се създава автоматично или ръчно на база на major incident или група от повтарящи се инциденти. Връзката е видима във формата: един Problem може да има много свързани инциденти, но един инцидент е свързан само с един problem.
Етапи на Root Cause Analysis (RCA)
- Идентифициране и регистриране: Problem записът се класифицира, например като Hardware, Software или Network.
- Разследване: Екипът по Problem Management използва RCA методологии като 5 Whys и Ishikawa, за да открие източника на грешката.
- Workaround: Преди постоянното отстраняване се определя временно решение (Workaround). То се записва в problem записа и се свързва със съответните инциденти, което позволява на агентите бързо да адресират симптомите, докато трайното решение се подготвя.
- Known Error: След като първопричината и workaround-ът бъдат дефинирани, problem записът се превръща в Known Error. Това е изключително важно за споделяне на знания и предотвратяване на многократни разследвания на един и същи проблем.
ЧАСТ III: Change Management: Контрол върху риска и стабилността
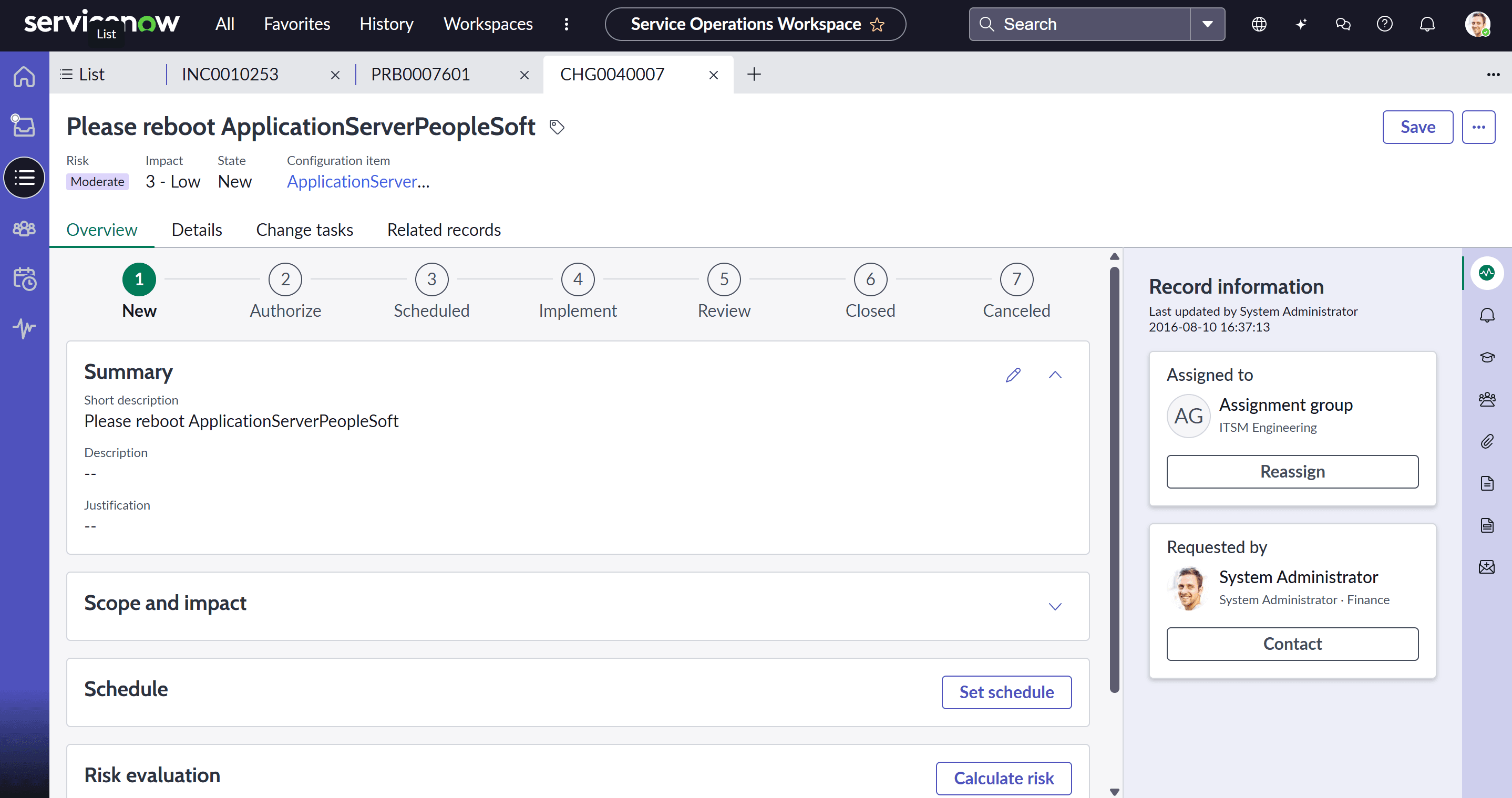
Change Management е процесът, който гарантира, че промените в ИТ средата се извършват по стандартизирани методи и процедури, така че да се максимизират ползите и да се минимизират рисковете.
ServiceNow предоставя стабилна, готова за използване архитектура, която разчита на класификация на промените, за да автоматизира workflow-а по одобрение.
Видове промени
- Standard Change: Предварително одобрени, нискорискови и чести промени, например създаване на имейл акаунт. Не изискват CAB одобрение.
- Normal Change: По-значими промени, които изискват пълна оценка на риска и формално одобрение, обикновено от CAB.
- Emergency Change: Промени, които трябва да бъдат приложени незабавно за разрешаване на major incident. Те имат ускорен, а често и ретроактивен процес на одобрение.
Интеграция с CMDB и откриване на конфликти
- Ключов OOTB елемент е възможността Change записът да бъде свързан със засегнатия Configuration Item (CI) от CMDB.
- Conflict Detection: ServiceNow автоматично проверява дали предложената промяна влиза в конфликт с други планирани промени или с Maintenance Window на CI, като предоставя и оценка на риска.
CAB Workbench е централният OOTB интерфейс за одобрение на промени. Той превръща срещите на Change Advisory Board от ръчен, имейл-базиран процес в структуриран дигитален процес чрез:
- преглед на предложените промени;
- документиране на CAB гласувания и решения;
- автоматично обновяване на статуса на промяната след взето решение.
ЧАСТ IV: Request Fulfillment: Ориентирано към потребителя предоставяне на услуги
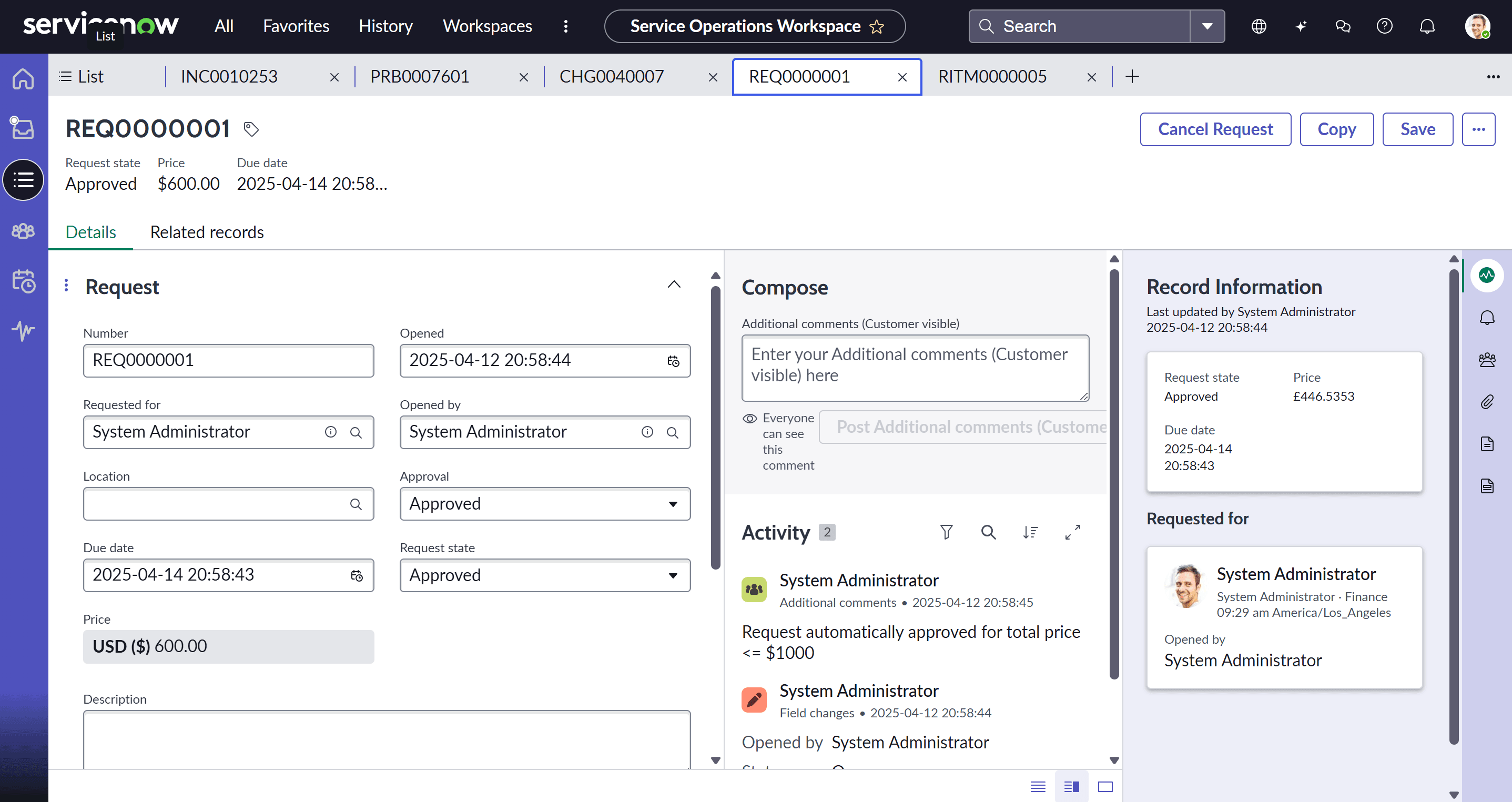
Request Fulfillment управлява жизнения цикъл на всички заявки за услуги от потребители, а не само прекъсванията. Това включва достъп до приложения, ново оборудване, информация и други услуги.
Service Catalog е визуалният интерфейс, който позволява на потребителите да заявяват ИТ услуги по начин, подобен на онлайн пазаруване.
Основни елементи
- Catalog Items: Всяка услуга е дефинирана като отделен артикул, с цена (ако е приложимо) и персонализирани полета (Catalog Variables), които събират точната информация, необходима на екипа по изпълнение.
- Потребителско изживяване: Артикулите са интуитивно групирани. OOTB интерфейсът е проектиран за incident deflection — потребителят търси заявка и получава предложения за knowledge articles още преди да създаде тикет.
Истинската стойност на Request Fulfillment е в автоматизацията на workflow-а
- Request (REQ): Първоначалното регистриране.
- Requested Item (RITM): Конкретният екземпляр на заявената услуга.
- Fulfillment Task (SCTASK): Задачи, възложени на работни групи като ИТ екип, procurement екип или HR екип.
Вместо сложен scripting, Flow Designer позволява на администраторите визуално да изграждат approval flow-и например от Manager, Service Owner или Budget Owner и автоматично да генерират задачи за правилните екипи, осигурявайки бързо и безгрешно изпълнение.
Заключение: ITSM основата в платформата ServiceNow
ITSM основата не е просто съвкупност от процеси, а непрекъснат цикъл на подобрение.
Един major Incident може да доведе до Problem. Разрешаването на Problem изисква Change. За да стане решението достъпно за крайния потребител, то може да бъде предложено чрез Request, например за достъп.
Чрез обединяването на Incident, Problem, Change и Request в платформата ServiceNow, организациите получават цялостна видимост, елиминират силозите и ускоряват дигиталната трансформация. Тази интегрирана основа позволява на ИТ да премине от управление на прекъсвания към проактивно и интелигентно предоставяне на услуги, превръщайки се в съществен двигател на бизнес стойност.
FAQ
1. Кои са основните ITSM процеси в ServiceNow?
Основните ITSM процеси в ServiceNow са Incident Management, Problem Management, Change Management и Request Fulfillment.
2. Какво представлява Incident Management в ServiceNow?
Това е процесът за бързо възстановяване на услугите след прекъсване с минимално влияние върху бизнеса.
3. Каква е разликата между Incident и Problem Management?
Incident решава проблема бързо, Problem търси и премахва първопричината.
4. Каква е ролята на Change Management?
Да осигури контролирано внедряване на промени с минимален риск.
5. Какви видове промени има?
Standard, Normal и Emergency Change.
6. Какво е Request Fulfillment?
Процесът за управление на заявки за услуги от потребителите.
7. Какво е Service Catalog?
Интерфейс, чрез който потребителите заявяват услуги.
8. Как ServiceNow подобрява ITSM?
Чрез автоматизация, централизация и по-добра видимост.
9. Защо интеграцията е важна?
Защото премахва силози и подобрява ефективността.
10. Как работят процесите заедно?
Като цикъл: Incident → Problem → Change → Request.


